A Technical Conversation about all of our Authentication Headaches
As you might’ve noticed, we’ve recently launched our new auth stack, giving an easier and more robust method of accessing Contenda to our valued current and future users. I thought it’d be interesting to talk about the process and the technological challenges we faced, so strap in… this might get a bit technical!
First of all, some clarification on what we mean by “auth”, as these two closely related topics are often mentioned under the same umbrella. Authentication and authorization are like a bouncer and a VIP list at an exclusive club.
- Authentication is the burly bouncer at the door, checking IDs to make sure you are who you say you are.
- Authorization is the VIP list they hold in their hand, determining whether you get access to the general area or the exclusive room upstairs. Just because you’ve passed the bouncer doesn’t mean you get access to the fancy VIP area – you need both the right ID and your name on the special list.
In our case, we were confident we could handle any authorization woes ourselves… and actually—letting you in on a little secret here—we have been all along: you’ve always had a workspace, even though we never really surfaced that. Just some thinking ahead on our part, knowing we’d get here soon.
Weapon of choice
However entertaining it is to watch Christopher Walken waltz his way across a hotel lobby, I’m talking about choosing our authentication provider. The “don’t roll your own security” line of wisdom is well known, and we agree. While there are some “obvious” choices, like Okta or Auth0, we didn’t necessarily want to go with them. They are huge, which means you’re not really special as a client… if something is wrong, you’re often on your own, unless you pay the big $$$ for the enterprise support contracts. (Also, these big players often have business practices that we’d call unfriendly at best, as in, when you hit an arbitrary number of users a month they make their service suddenly cost a magnitude more than before.)
We looked at roughly 10 different providers overall, and while many were promising we had to cut a bunch simply due to them not supporting some part of our tech stack (React frontend, Python backend). After some deliberation, we ended up choosing FusionAuth, an option with friendlier pricing than most. It was also important for us that they’d handle their own hosting, so that’s one less problem we have to deal with.
What we had to do
Ever since the beginning, we wanted our users to access Contenda in the way that’s most convenient to them: let our technical users use an API to potentially automate things, but also have a friendly way of working with us on the web for everyone. This means that whatever authentication stack we choose, we need to make sure both of these avenues are supported and secure.
Sadly, this also means that we are off the beaten path, as this is not a typical scenario for most services. In practice, we couldn’t just use a prepared wrapper for React web apps, we had to implement things ourselves both on the backend and on the frontend.
To properly support our web app, we implemented the beautifully named “Authorization Code Flow with Proof Key for Code Exchange (PKCE)”, also known as the “pixie” flow. This is the currently safest and best way to let web apps authenticate securely, without exposing any authentication secrets to clients (who could then read those out from the source code or using the browser dev tools). This is done by having the backend do most of the heavy lifting, and only asking information from the client that the client itself created (therefore there isn’t really anything there that an evil actor could try and steal).
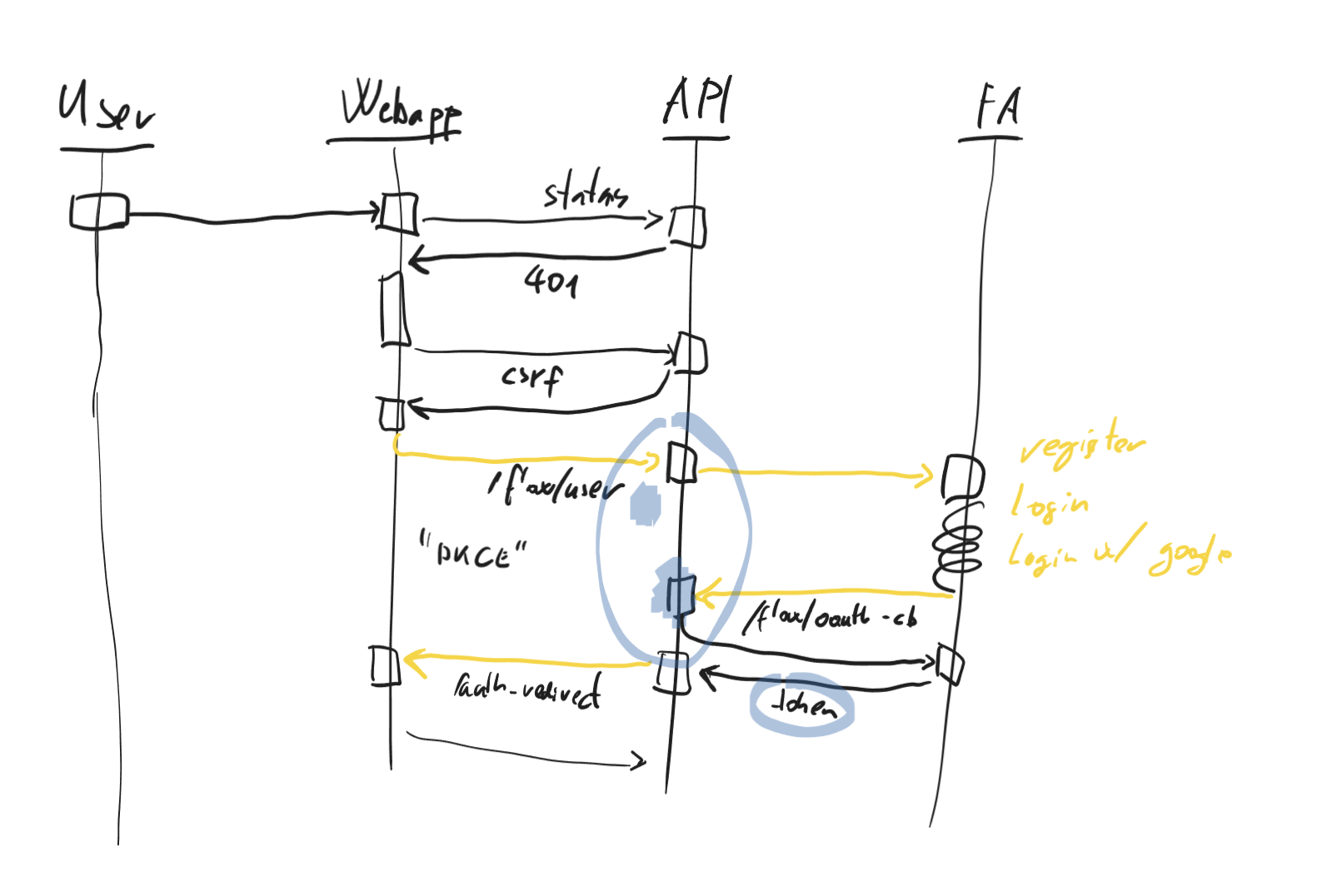
(A screencap from my explanation of our auth flow to the fellow engineers at Contenda.)
This flow of course doesn’t really work for a typical API, so to make that path happen we decided to use one of FusionAuth’s unique features: Application Authentication Tokens. (Although I can imagine us shifting towards something like the Client Credentials Grant eventually, depending on how various future integrations might shake out.)
What we didn’t think we had to do
No major development effort goes without issues, and that was true for this one as well. It’s an age-old adage in the world of (web) development: the only constant is change. Recently, these shifts have been driven in large part by an increased focus on privacy and security, particularly around the use and management of cookies. Which is great - obviously - but also made our lives a bit harder.
If you happened to have played around with our API recently, you might’ve noticed we’ve changed our API domains from .io to .co, now matching our web app. I personally like having the separation between API and app on the domain level, but our hands were essentially forced by what I’m about to describe.

Cookies have been the cornerstone of the web for years, serving numerous purposes from personalizing user experiences to tracking user activity for analytics. However, they are also critical for managing user authentication… and now you can probably see where the problem was. Recent advancements in browser security measures have introduced new challenges that we had to overcome: having our backend and frontend be on different domains essentially meant we were trying to work with third-party cookies.
Third-party cookies are set by a website different from the one you’re currently visiting and are commonly used for cross-domain tracking, advertising and cross-domain authentication. Except not anymore, as in an effort to combat privacy concerns related to user tracking and personal data usage, popular browsers have started to block third-party cookies by default already (or very soon). Similarly, the SameSite attribute’s behavior and defaults have been changed too - also to strengthen security, but coincidentally make cross-domain authentication harder.
While theoretically these challenges are solvable, our testing revealed that some cases (such as incognito/private windows) were completely broken already, and even our “happy path” was deemed unreliable for reasons still mostly unknown to us. So as I mentioned above, we ended up accepting the new reality, and committing to the hassle-hurdle of moving our API over to a new TLD that hasn’t really been inside our AWS umbrella before.
What’s still coming
This work is never really done, as the cat and mouse game between malicious actors and security experts never stops. Cross-Site Request Forgery, Cross-Site Scripting and more, all hopefully crossed out from the potential issues… but who know what comes next. At minimum we’re committed to keep up with the best security practices, but our aim is to make our auth flows the best and painless they can be, e.g., adding more social sign-in options for your convenience.
Photo of a cookie by Vyshnavi Bisani on Unsplash